本文最后更新于 259 天前,如有错误请邮件至 zhiligyi222na@gmail.com
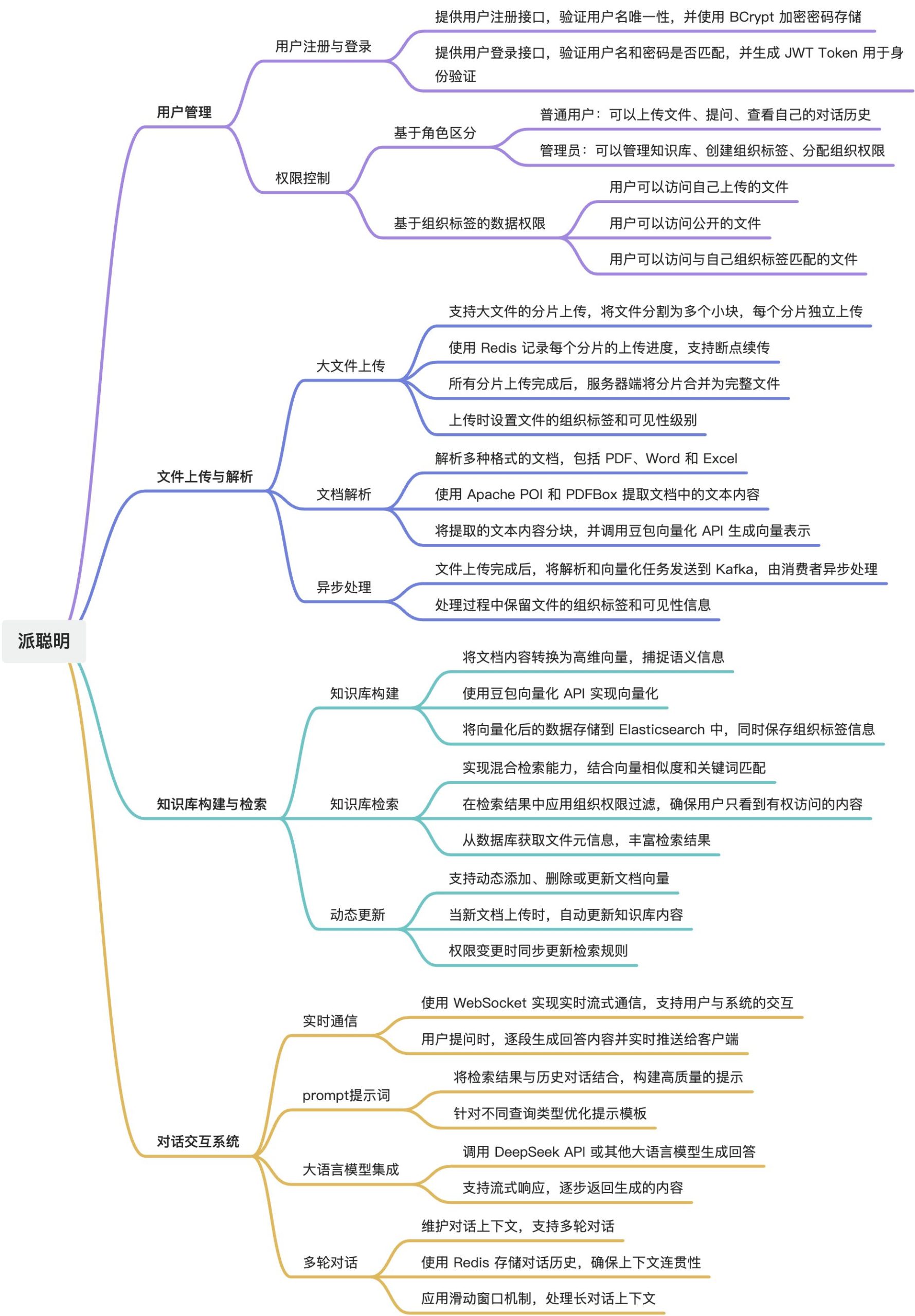
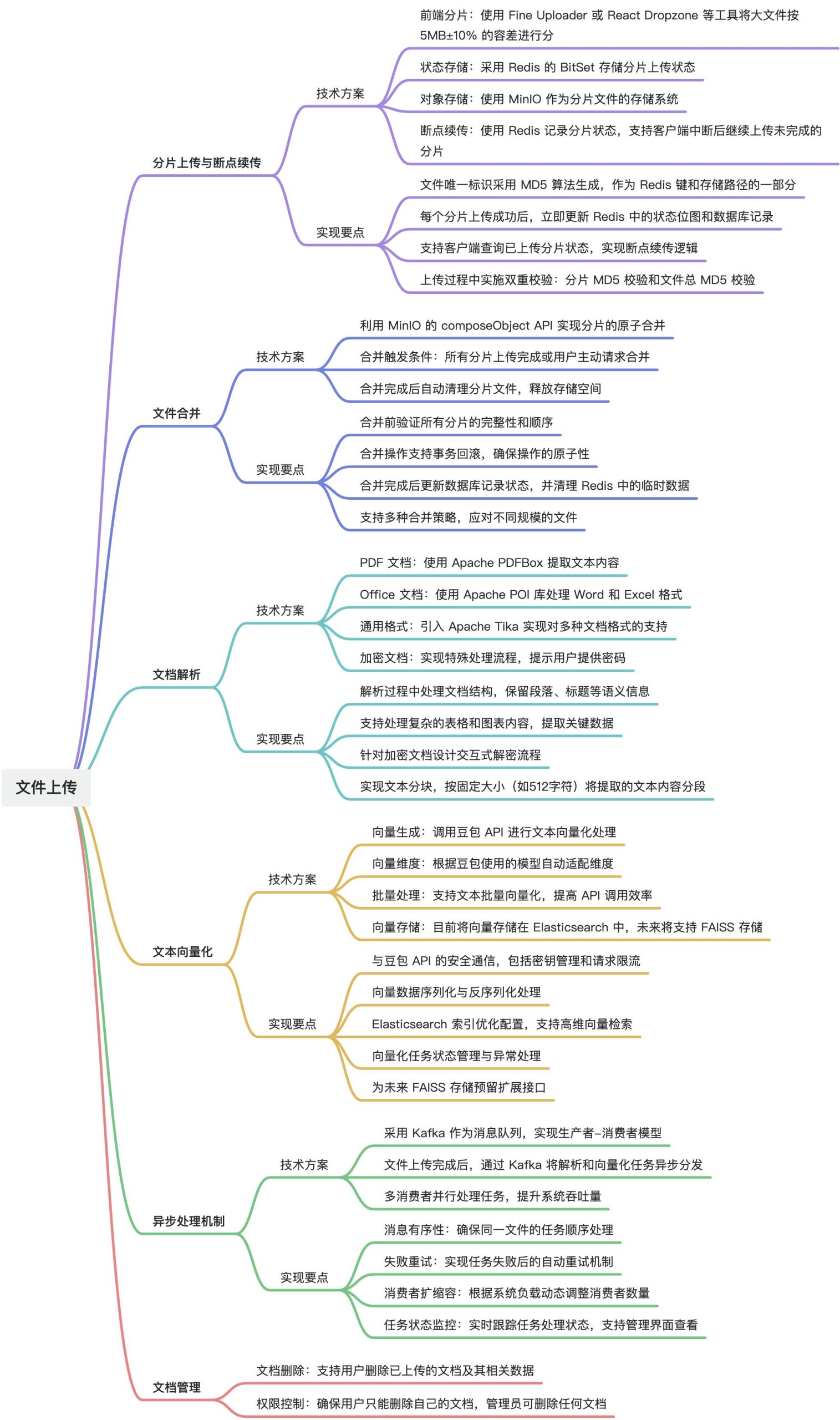
文件上传与解析模块实现了大文件的分片上传、断点续传、文件合并以及文档解析功能。
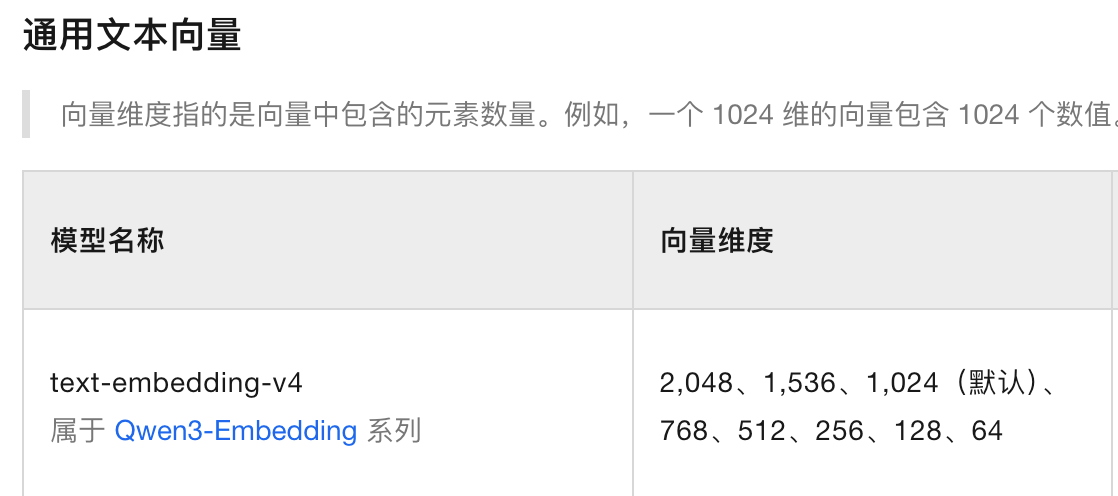
通过 Redis 和 MinIO 的结合,确保大文件上传的可靠性;并通过 Kafka 实现异步处理。模块支持多种文档格式(PDF、Word、Excel)的解析,并提取文本内容用于后续向量化处理。文本向量化通过调用豆包 API 实现,生成的向量数据目前存储在 Elasticsearch 中,未来将同时支持 FAISS 存储。
一、核心功能设计
二、数据流转与存储设计
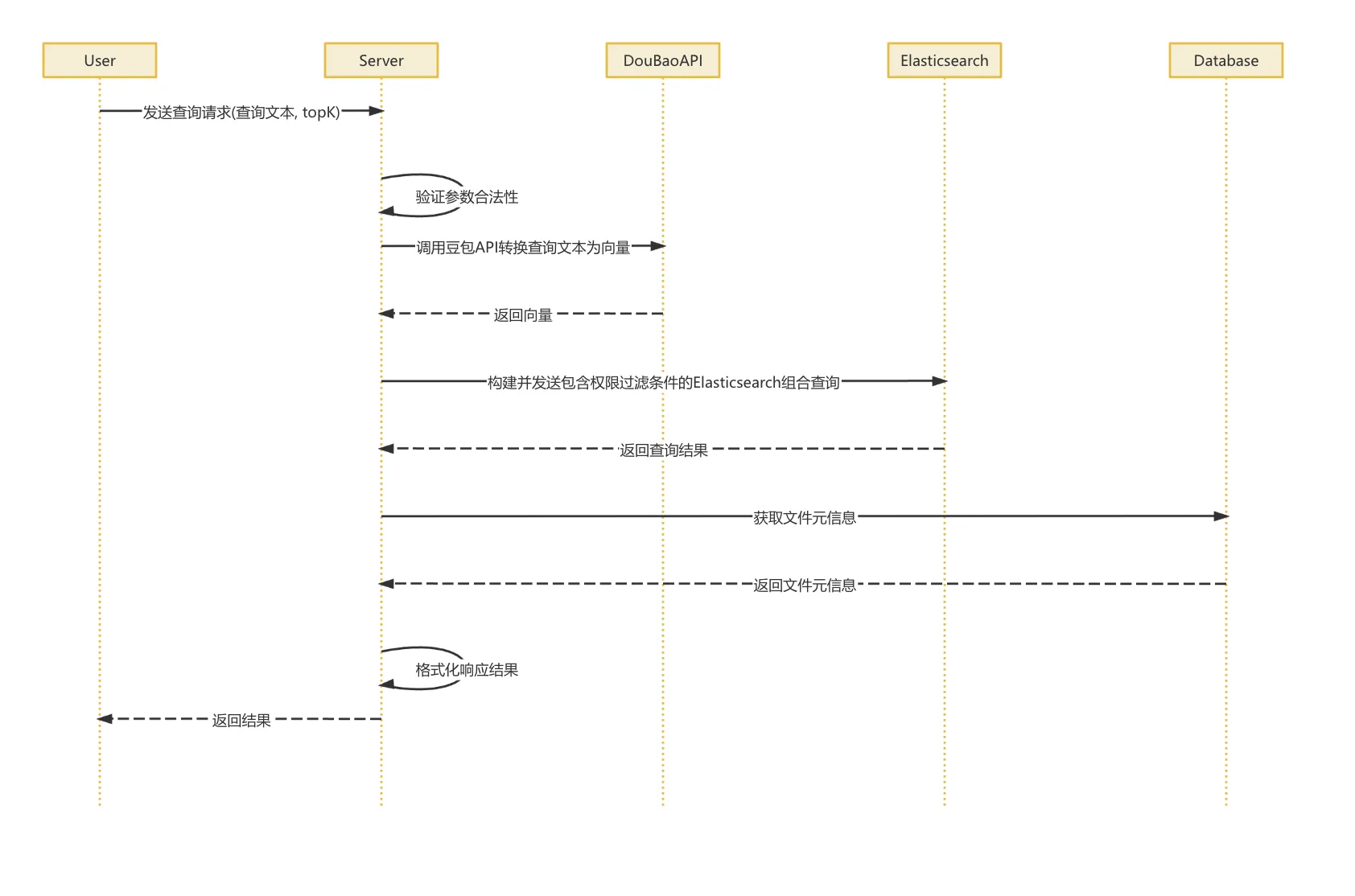
文件从上传到向量化完成的完整流程:
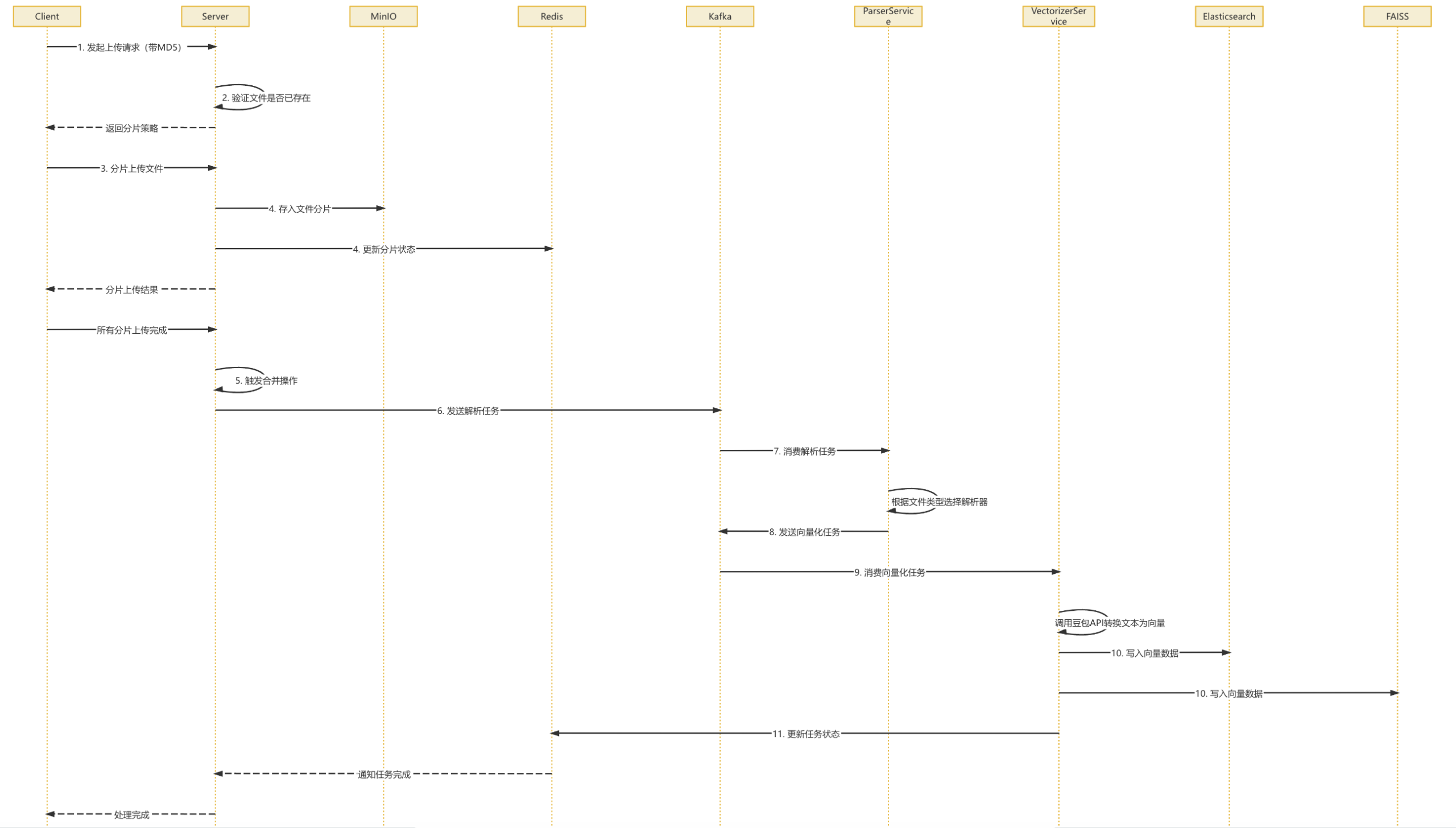
- 客户端计算文件 MD5,发起上传请求→服务端验证文件是否已存在,返回分片策略
- 客户端根据策略分片上传文件
- 服务端接收分片,存入 MinIO 并更新 Redis 状态
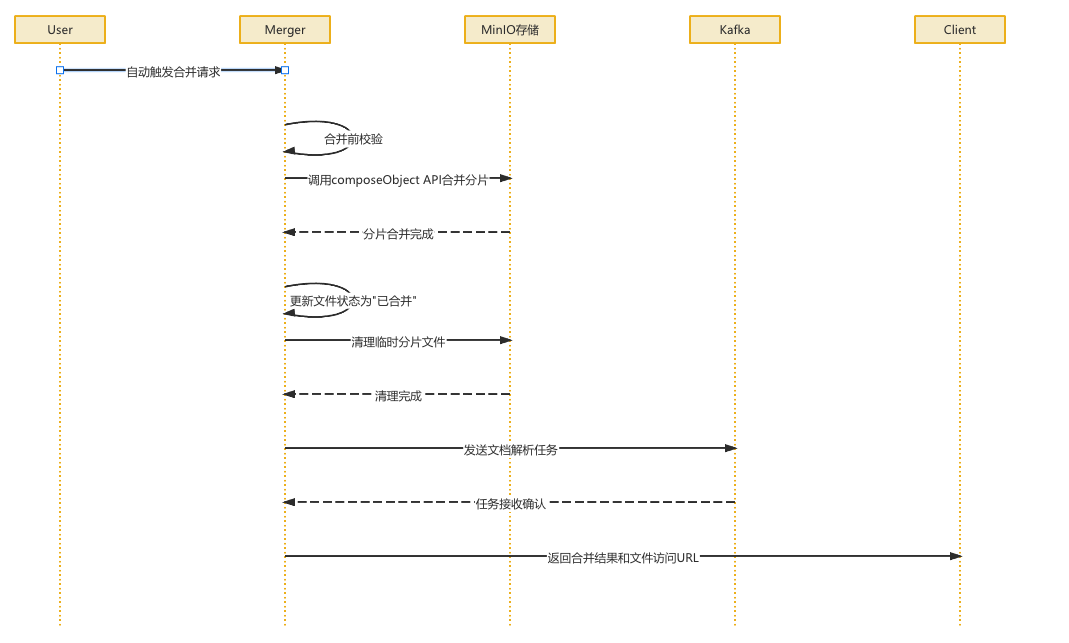
- 所有分片上传完成后,触发合并操作
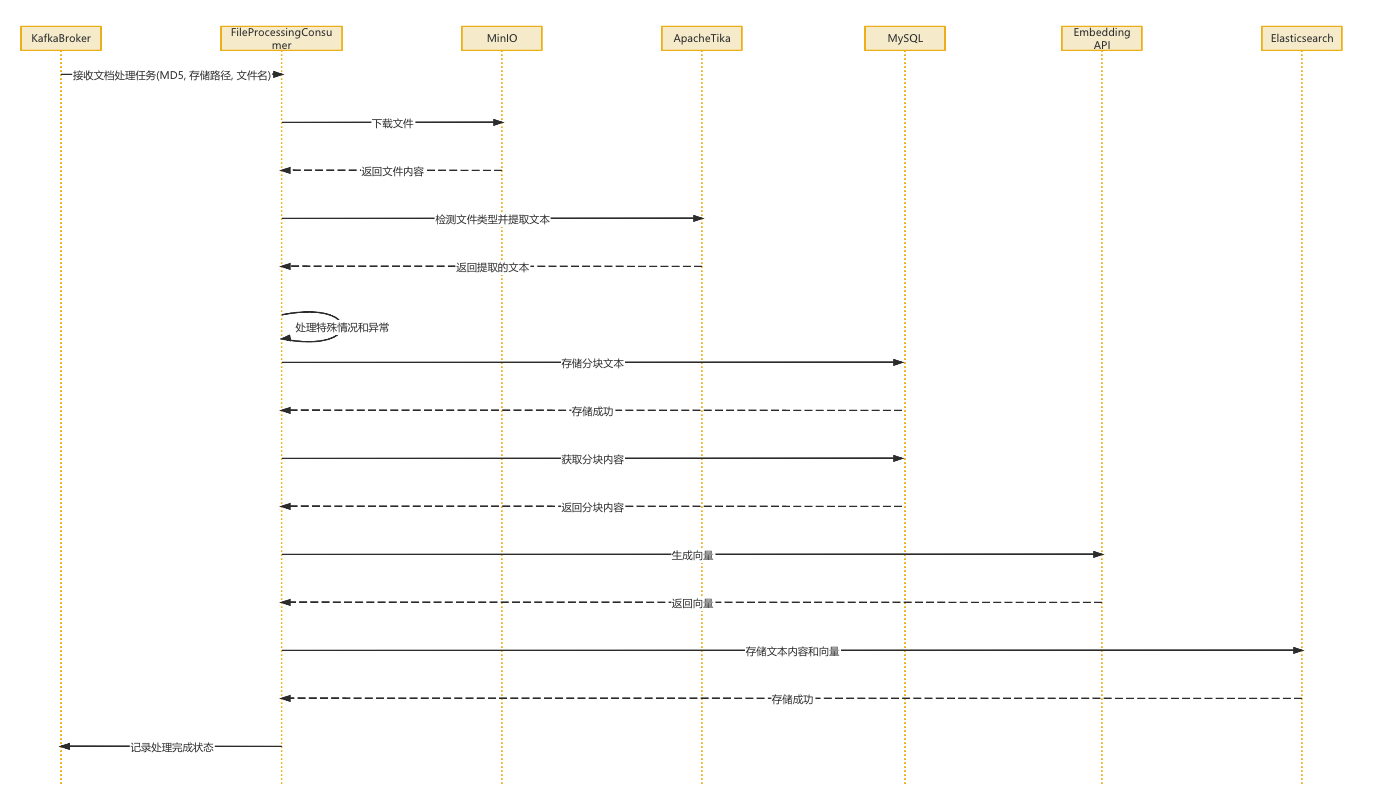
- 合并完成后发送解析任务到 Kafka→解析服务消费任务,根据文件类型选择相应解析器提取文本
- 文本分块后发送向量化任务到 Kafka→向量化服务消费任务,调用豆包 API 将文本转换为向量表示
- 向量数据写入 Elasticsearch 和预留 FAISS 接口→更新任务状态,通知用户处理完成
01、MySQL
文件主表(file_upload):存储文件元信息,如 MD5、名称、大小、状态
分片表(chunk_info):记录每个分片的信息,包括索引、MD5、存储路径
解析结果表(document_vectors):存储文本分块和向量化结果的元数据
02、Redis
使用 BitSet 记录已上传分片的位图(SETBIT命令); 存储上传任务的临时状态和进度; 缓存热点文件的元数据,减轻数据库压力
03、MinIO
临时分片:存储上传的文件分片,路径结构为/temp/{fileMd5}/{chunkIndex}
完整文件:合并后的文件存储在/documents/{userId}/{fileName}
存储策略:实现热冷数据分离
04、 Elasticsearch
存储文本向量数据和原始文本内容,索引基于文件 MD5 和分块 ID 组织
三、关键流程
01. 分片上传流程

02. 文件合并流程
03.文档处理流程(合并解析和向量化)
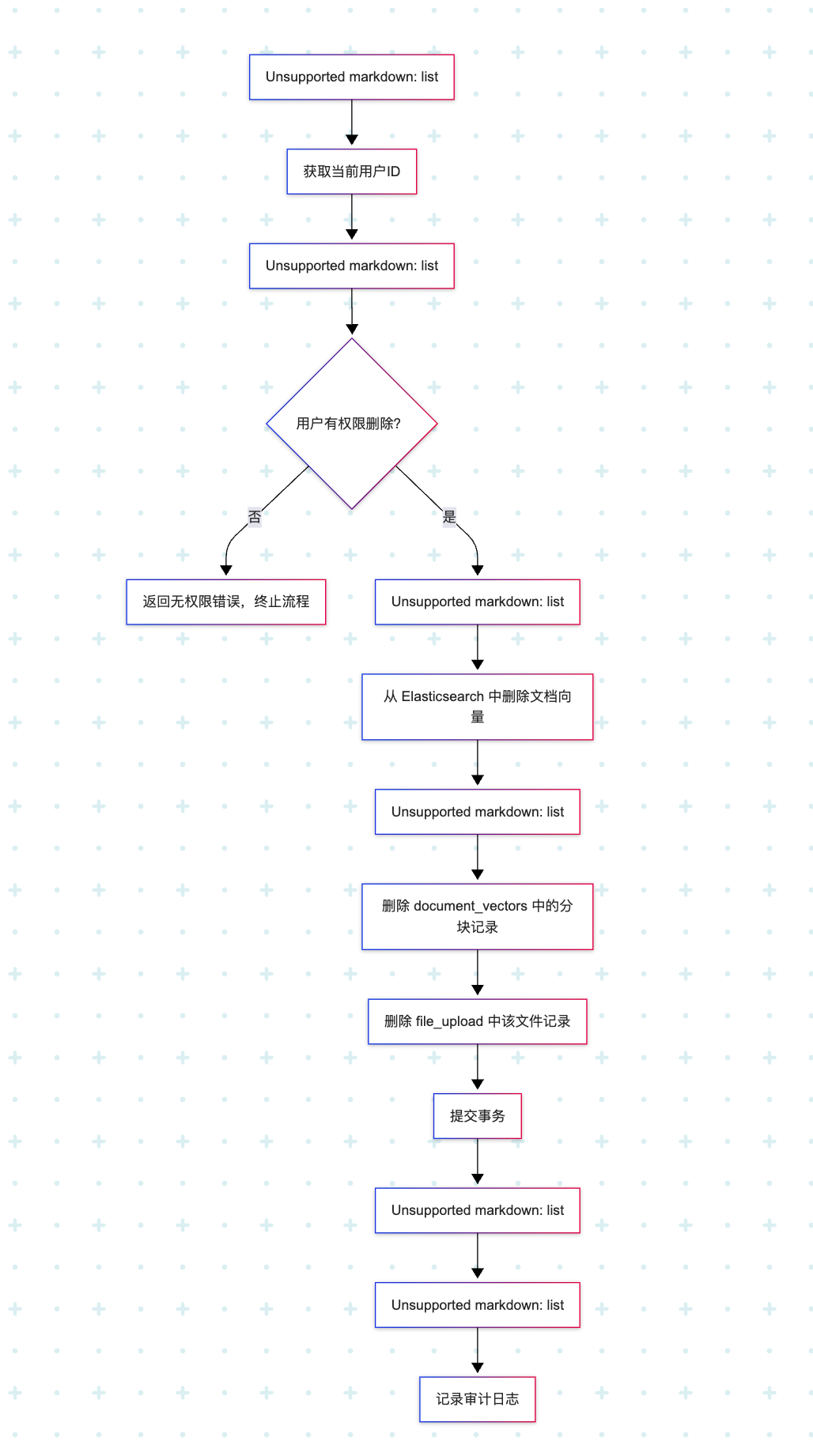
04.文档删除流程
四、接口设计
01、分片上传接口
基本信息
- URL:
/api/v1/upload/chunk - Method:
POST - Headers
Authorization: Bearer {token}
- Body (multipart/form-data)
fileMd5: d41d8cd98f00b204e9800998ecf8427e // 文件MD5值(必需)
chunkIndex: 3 // 分片索引(必需)
totalSize: 15728640 // 文件总大小(必需)
fileName: 年度报告.pdf // 文件名(必需,现在支持中文)
totalChunks: 64 // 总分片数量(可选)
orgTag: DEPT_A // 组织标签(可选,默认用户主组织标签)
isPublic: true // 是否公开(可选,默认false)
file: [分片二进制数据] // 分片文件数据(必需)
- Response
成功响应
{
"code": 200,
"message": "分片上传成功",
"data": {
"uploaded": [0, 1, 2, 3],
"progress": 75.0
}
}
失败响应
{
"code": 500,
"message": "分片上传失败: 具体错误信息"
}
02、查询上传状态接口
- URL:
/api/v1/upload/status - Method:
GET - Query Parameters:
- file_md5: d41d8cd98f00b204e9800998ecf8427e
- Headers:
Authorization: Bearer {token}
- Response:
- 成功:
{
"code": 200,
"message": "Success",
"data": {
"uploaded": [0, 1, 2],
"progress": 60.0,
"total_chunks": 5
}
}
- 失败:
{
"code": 404,
"message": "Upload record not found"
}
03、文件合并接口
- URL:
/api/v1/upload/merge - Method: POST
- Headers:
Authorization: Bearer {token}
- Request Body:
{
"file_md5": "d41d8cd98f00b204e9800998ecf8427e",
"file_name": "年度报告.pdf"
}
- Response:
- 成功:
{
"code": 200,
"message": "File merged successfully",
"data": {
"object_url": "https://minio.example.com/reports/年度报告.pdf",
"file_size": 15728640
}
}
- 失败:
{
"code": 400,
"message": "Not all chunks have been uploaded"
}
04、文件删除接口
- URL:
/api/v1/documents/{file_md5} - Method: DELETE
- Path Parameters:
file_md5: 要删除的文件唯一标识(MD5值)
- Headers:
Authorization: Bearer {token} (用于身份验证)
- Response:
- 成功:
{
"status": "success",
"message": "文档删除成功"
}
- 文档不存在:
{
"status": "error",
"message": "文档不存在"
}
- 权限不足:
{
"status": "error",
"message": "没有权限删除此文档"
}
- 服务器错误:
{
"status": "error",
"message": "删除文档失败: 详细错误信息"
}
05、获取用户可访问的全部文件列表接口
获取当前用户可以访问的所有文件列表,包括用户上传的文件、公开文件以及用户所属组织的文件。
- URL:
/api/v1/documents/accessible - 方法:
GET - Headers:
Authorization: Bearer {token} (用于身份验证)
- Response:
- 成功:
{
"status": "success",
"data": [
{
"fileMd5": "a1b2c3d4e5f6g7h8i9j0",
"fileName": "文档1.pdf",
"totalSize": 1048576,
"status": 1,
"userId": "user123",
"orgTag": "DEPT_FINANCE",
"isPublic": true,
"createdAt": "2023-10-01T10:30:00",
"mergedAt": "2023-10-01T10:35:00"
},
// ... 更多文件
]
}
- 失败:
{
"status": "error",
"message": "获取文件列表失败: {具体错误信息}"
}
06、获取用户上传的全部文件列表接口
获取当前用户上传的所有文件列表。
- URL:
/api/v1/documents/uploads - 方法:
GET - Headers:
Authorization: Bearer {token} (用于身份验证)
- Response:
- 成功:
{
"status": "success",
"data": [
{
"fileMd5": "a1b2c3d4e5f6g7h8i9j0",
"fileName": "我的文档.pdf",
"totalSize": 1048576,
"status": 1,
"userId": "user123",
"orgTagName": "DEPT_FINANCE",
"isPublic": true,
"createdAt": "2023-10-01T10:30:00",
"mergedAt": "2023-10-01T10:35:00"
},
// ... 更多文件
]
}
- 失败
{
"status": "error",
"message": "获取文件列表失败: {具体错误信息}"
}
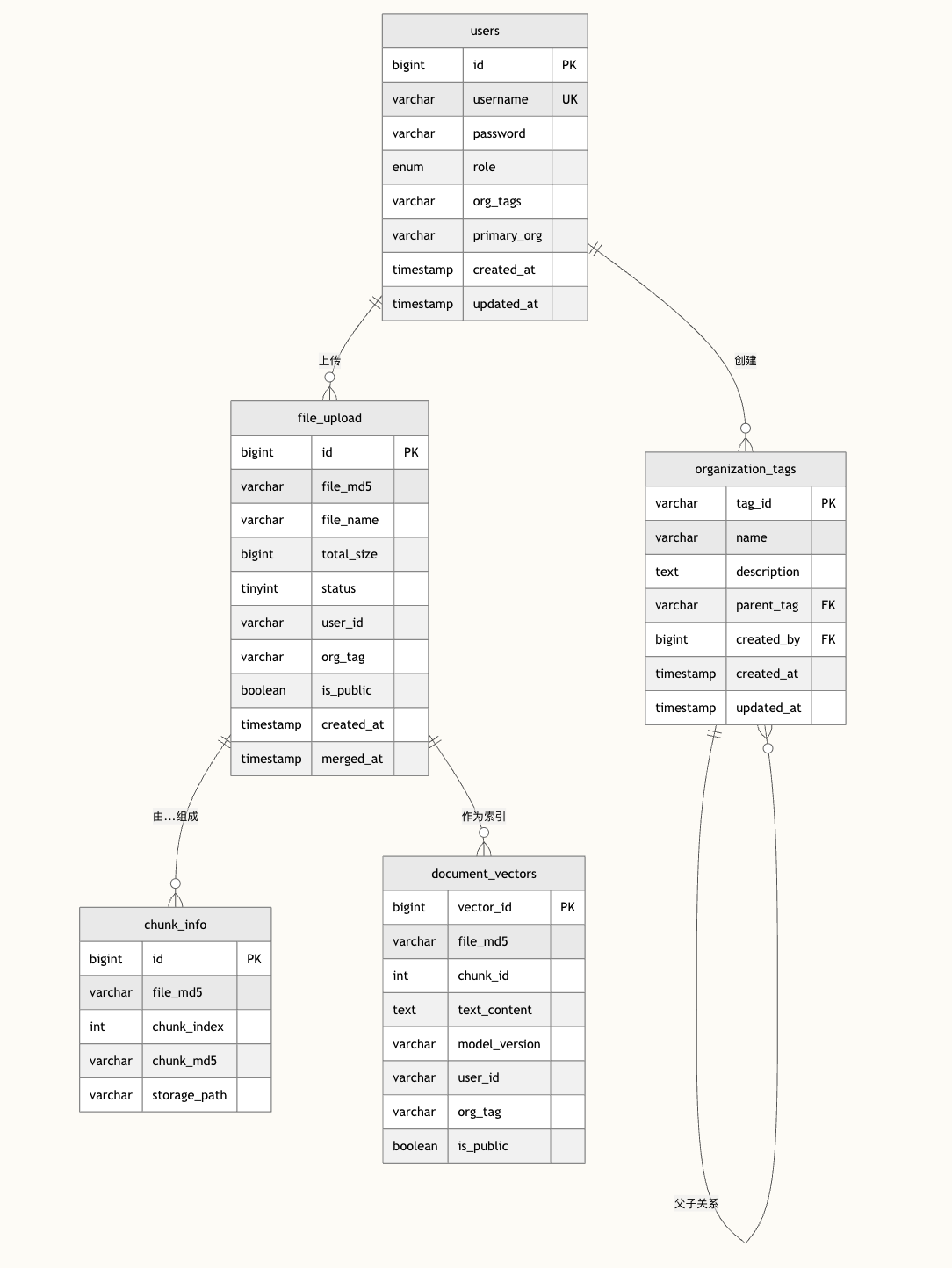
五、数据库设计
01、文件主表 (file_upload)
CREATE TABLE file_upload (
file_md5 VARCHAR(32) PRIMARY KEY COMMENT '文件的MD5值,作为主键唯一标识文件',
file_name VARCHAR(255) NOT NULL COMMENT '文件的原始名称',
total_size BIGINT NOT NULL COMMENT '文件总大小(字节)',
status INT NOT NULL DEFAULT 0 COMMENT '文件上传状态:0-上传中,1-已完成',
user_id VARCHAR(64) NOT NULL COMMENT '上传用户的标识符',
org_tag VARCHAR(50) COMMENT '文件所属组织标签',
is_public BOOLEAN NOT NULL DEFAULT FALSE COMMENT '文件是否公开',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '文件上传创建时间',
merged_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '文件合并完成时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文件上传记录表';
02、分片表 (chunk_info)
CREATE TABLE chunk_info (
id BIGINT AUTO_INCREMENT PRIMARY KEY COMMENT '分块记录唯一标识',
file_md5 VARCHAR(32) NOT NULL COMMENT '关联的文件MD5值',
chunk_index INT NOT NULL COMMENT '分块序号',
chunk_md5 VARCHAR(32) NOT NULL COMMENT '分块的MD5值',
storage_path VARCHAR(255) NOT NULL COMMENT '分块在存储系统中的路径'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文件分块信息表';
03、解析结果表 (document_vectors)
CREATE TABLE document_vectors (
vector_id BIGINT AUTO_INCREMENT PRIMARY KEY COMMENT '向量记录唯一标识',
file_md5 VARCHAR(32) NOT NULL COMMENT '关联的文件MD5值',
chunk_id INT NOT NULL COMMENT '文本分块序号',
text_content TEXT COMMENT '文本内容',
model_version VARCHAR(32) COMMENT '向量模型版本',
user_id VARCHAR(64) NOT NULL COMMENT '上传用户ID',
org_tag VARCHAR(50) COMMENT '文件所属组织标签',
is_public BOOLEAN NOT NULL DEFAULT FALSE COMMENT '文件是否公开'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文档向量存储表';