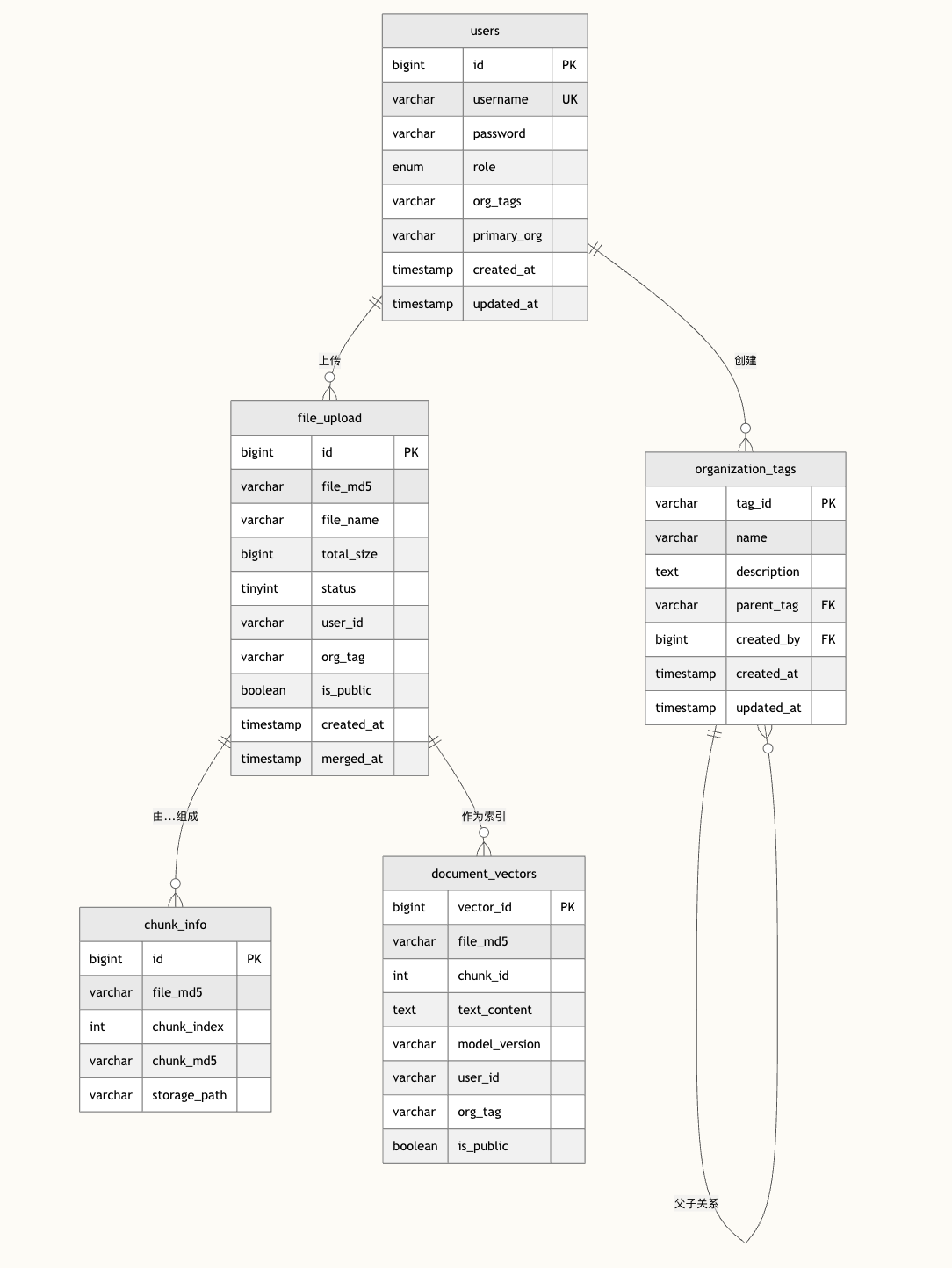
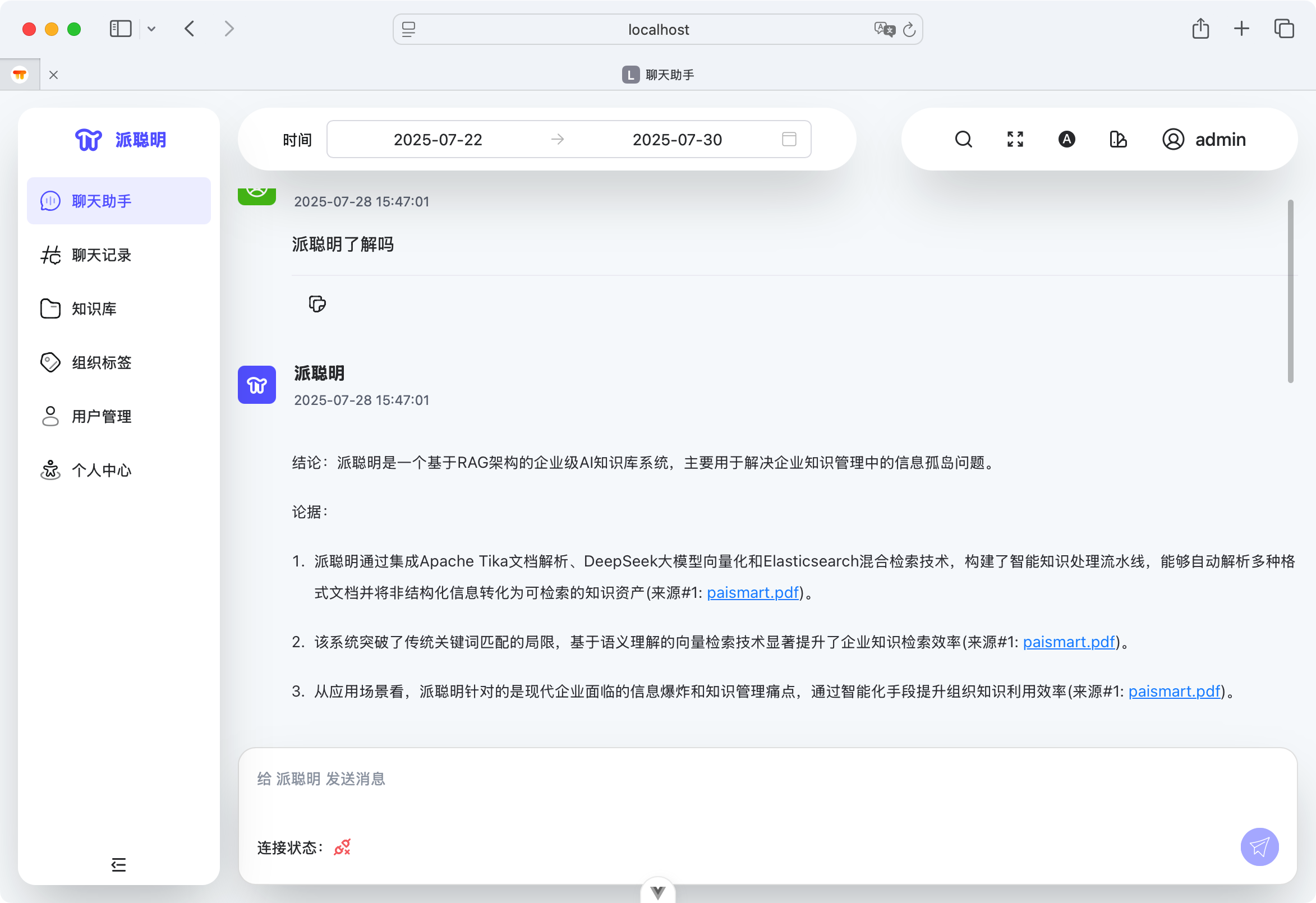
一、用户表 (users)
users 表不仅存储了基础的用户认证信息(用户名、加密密码),更重要的是实现了基于组织的权限管理体系。通过 role 字段区分普通用户和管理员, org_tags 字段支持用户归属多个组织标签(逗号分隔),而 primary_org 则标识用户的主要组织归属。这种设计使得派聪明能够在企业环境中实现细粒度的多租户权限控制,确保不同组织的用户只能访问属于自己组织的知识资源。
| 字段名 | 数据类型 | 是否主键 | 描述 |
|---|---|---|---|
| id | BIGINT | 是 | 用户唯一标识 |
| username | VARCHAR(255) | 否 | 用户名,唯一 |
| password | VARCHAR(255) | 否 | 加密后的密码 |
| role | ENUM(‘USER’, ‘ADMIN’) | 否 | 用户角色 |
| org_tags | VARCHAR(255) | 否 | 用户所属组织标签,多个用逗号分隔 |
| primary_org | VARCHAR(50) | 否 | 用户主组织标签 |
| created_at | TIMESTAMP | 否 | 创建时间 |
| updated_at | TIMESTAMP | 否 | 更新时间 |
建表语句:
CREATE TABLE users (
id BIGINT AUTO_INCREMENT PRIMARY KEY COMMENT '用户唯一标识',
username VARCHAR(255) NOT NULL UNIQUE COMMENT '用户名,唯一',
password VARCHAR(255) NOT NULL COMMENT '加密后的密码',
role ENUM('USER', 'ADMIN') NOT NULL DEFAULT 'USER' COMMENT '用户角色',
org_tags VARCHAR(255) DEFAULT NULL COMMENT '用户所属组织标签,多个用逗号分隔',
primary_org VARCHAR(50) DEFAULT NULL COMMENT '用户主组织标签',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
INDEX idx_username (username) COMMENT '用户名索引'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
二、组织标签表organization_tags
organization_tags 表支持层级化的组织标签结构。通过 parent_tag 父标签 ID,可以构建树形的组织架构(如:公司 -> 部门 -> 小组)。
每个标签都有创建者追踪( created_by ),确保组织管理的可追溯性。
在实际业务中,这些组织标签会与文档权限、用户访问控制紧密结合,实现基于组织的知识隔离和共享策略。比如,技术部门的文档只有技术部门的用户可以访问,而公司级别的公告则所有用户都能看到。
| 字段名 | 数据类型 | 是否主键 | 描述 |
|---|---|---|---|
| tag_id | VARCHAR(50) | 是 | 标签唯一标识 |
| name | VARCHAR(100) | 否 | 标签名称 |
| description | TEXT | 否 | 描述 |
| parent_tag | VARCHAR(50) | 否 | 父标签ID |
| created_by | BIGINT | 否 | 创建者ID |
| created_at | TIMESTAMP | 否 | 创建时间 |
| updated_at | TIMESTAMP | 否 | 更新时间 |
建表语句:
CREATE TABLE organization_tags (
tag_id VARCHAR(50) PRIMARY KEY COMMENT '标签唯一标识',
name VARCHAR(100) NOT NULL COMMENT '标签名称',
description TEXT COMMENT '描述',
parent_tag VARCHAR(50) DEFAULT NULL COMMENT '父标签ID',
created_by BIGINT NOT NULL COMMENT '创建者ID',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
FOREIGN KEY (parent_tag) REFERENCES organization_tags(tag_id) ON DELETE SET NULL,
FOREIGN KEY (created_by) REFERENCES users(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='组织标签表';
三、文件主表 (file_upload)
file_upload 表记录了每个文件的完整生命周期。
通过 file_md5 实现文件去重,避免重复存储相同内容的文档。 status 字段追踪文件的处理状态(上传中、已完成、处理失败等), org_tag 字段将文件与组织权限绑定, is_public 控制文件的可见性范围。 uk_md5_user 唯一约束确保同一用户不会重复上传相同文件,而 idx_user、idx_org_tag 索引则保证了按用户、按组织查询文件时的高效性。这种设计支持了派聪明的智能文档管理功能,包括文件去重、权限控制和快速检索。
| 字段名 | 类型 | 描述 |
|---|---|---|
| id | BIGINT | 主键 |
| file_md5 | CHAR(32) PRIMARY KEY | 文件指纹 |
| file_name | VARCHAR(255) | 文件名 |
| total_size | BIGINT UNSIGNED | 文件大小(字节数) |
| status | TINYINT(1) | 文件状态 |
| user_id | VARCHAR(64) | 用户标识 |
| created_at | DATETIME DEFAULT CURRENT_TIMESTAMP | 文件创建时间 |
| merged_at | DATETIME | 文件合并完成时间 |
建表语句:
CREATE TABLE file_upload (
id BIGINT NOT NULL AUTO_INCREMENT COMMENT '主键',
file_md5 VARCHAR(32) NOT NULL COMMENT '文件 MD5',
file_name VARCHAR(255) NOT NULL COMMENT '文件名称',
total_size BIGINT NOT NULL COMMENT '文件大小',
status TINYINT NOT NULL DEFAULT 0 COMMENT '上传状态',
user_id VARCHAR(64) NOT NULL COMMENT '用户 ID',
org_tag VARCHAR(50) DEFAULT NULL COMMENT '组织标签',
is_public BOOLEAN NOT NULL DEFAULT FALSE COMMENT '是否公开', created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
merged_at TIMESTAMP NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '合并时间',
PRIMARY KEY (id),
UNIQUE KEY uk_md5_user (file_md5, user_id),
INDEX idx_user (user_id),
INDEX idx_org_tag (org_tag)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文件上传记录';
四、分片表 (chunk_info)
chunk_info 表实现了派聪明的大文件分块上传和存储机制。
当用户上传大型文档时,系统会将文件切分成多个小块,每个分块都有独立的 MD5 校验和存储路径。这种设计不仅提高了大文件上传的可靠性(支持断点续传),还优化了存储和传输效率。在文档处理流程中,系统可以并行处理不同的文件分块,加速文档解析和向量化过程。同时,分块存储也为后续的文档版本管理和增量更新提供了技术基础。
CREATE TABLE chunk_info (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
file_md5 CHAR(32) NOT NULL COMMENT '外键',
chunk_index INT NOT NULL COMMENT '0-based',
chunk_md5 CHAR(32) NOT NULL COMMENT '分片校验',
storage_path VARCHAR(255) NOT NULL COMMENT 'MinIO路径',
CONSTRAINT fk_file_md5 FOREIGN KEY (file_md5) REFERENCES file_upload(file_md5),
INDEX idx_file_chunk (file_md5, chunk_index) -- 联合索引
) ENGINE=InnoDB;
五、解析结果表 (document_vectors)
document_vectors 表存储了文档经过 AI 模型处理后的向量化表示,每个文档会被切分成多个文本块( chunk_id ),每个文本块都有对应的向量表示。
text_content 保存原始文本内容,便于检索结果的展示和上下文理解。 model_version 字段支持向量模型的版本管理,当 AI 模型升级时可以识别需要重新向量化的文档。通过 user_id 、 org_tag 和 is_public 字段,向量检索也遵循相同的权限控制策略,确保用户只能检索到有权限访问的文档内容。
| 字段名 | 类型 | 描述 |
|---|---|---|
| vector_id | BIGINT AUTO_INCREMENT | 主键,自增ID |
| file_md5 | CHAR(32) | 文件指纹,用于关联file_upload表 |
| chunk_id | INT | 文本分块序号 |
| text_content | LONGTEXT | 原始文本内容 |
| model_version | VARCHAR(32) | 生成向量所使用的模型版本 |
CREATE TABLE document_vectors (
vector_id BIGINT AUTO_INCREMENT PRIMARY KEY,
file_md5 CHAR(32) NOT NULL,
chunk_id INT NOT NULL COMMENT '文本分块序号',
text_content LONGTEXT COMMENT '压缩存储',
model_version VARCHAR(32) DEFAULT 'all-MiniLM-L6-v2'
) ENGINE=InnoDB;
这五个表构成了派聪明完整的业务闭环:用户通过 users 表进行身份认证和权限管理,在 organization_tags 定义的组织架构下上传文档到 file_upload 表,大文件通过 chunk_info 表进行分块管理,最终文档内容在 document_vectors 表中向量化存储,为智能检索提供数据基础。